Redux 精華,第 7 部分:RTK Query 基礎
- RTK Query 如何簡化 Redux 應用程式的資料擷取
- 如何設定 RTK Query
- 如何使用 RTK Query 進行基本資料擷取和更新要求
- 完成本教學課程前幾節,以了解 Redux Toolkit 使用模式
如果您偏好影片課程,您可以在 Egghead 免費觀看由 RTK Query 建立者 Lenz Weber-Tronic 所製作的 RTK Query 影片課程,或在此處觀看第一堂課
簡介
在第 5 部分:非同步邏輯和資料擷取和第 6 部分:效能和正規化中,我們看到了 Redux 中用於資料擷取和快取的標準模式。這些模式包括使用非同步 thunk 擷取資料、使用結果發送動作、在儲存區中管理要求載入狀態,以及正規化快取資料,以便透過 ID 更輕鬆地查詢和更新個別項目。
在本部分中,我們將探討如何使用 RTK Query,這是一個專為 Redux 應用程式設計的資料擷取和快取解決方案,並了解它如何簡化擷取資料和在元件中使用資料的流程。
RTK Query 概觀
RTK Query 是一個強大的資料擷取和快取工具。它旨在簡化網頁應用程式中載入資料的常見情況,讓您無需親自撰寫資料擷取和快取邏輯。
RTK Query 是Redux Toolkit 套件中包含的選用附加元件,其功能建構在 Redux Toolkit 中其他 API 的基礎上。
動機
Web 應用程式通常需要從伺服器擷取資料才能顯示。它們通常也需要更新資料,將這些更新傳送至伺服器,並讓用戶端快取資料與伺服器上的資料保持同步。這會因為需要實作現今應用程式中使用的其他行為而變得更為複雜
- 追蹤載入狀態以顯示 UI 旋轉器
- 避免重複要求相同的資料
- 樂觀更新以使 UI 感覺更快
- 管理快取生命週期,因為使用者會與 UI 互動
我們已經看過如何使用 Redux Toolkit 實作這些行為。
然而,Redux 過去從未包含任何內建功能來協助完全解決這些使用案例。即使我們將 createAsyncThunk 與 createSlice 搭配使用,在提出要求和管理載入狀態時仍需要大量手動工作。我們必須建立非同步 thunk、提出實際要求、從回應中提取相關欄位、新增載入狀態欄位、在 extraReducers 中新增處理常式來處理 pending/fulfilled/rejected 案例,並實際撰寫適當的狀態更新。
在過去幾年中,React 社群已了解到「資料擷取和快取」實際上與「狀態管理」是兩組不同的考量。雖然你可以使用 Redux 等狀態管理函式庫來快取資料,但使用案例已經足夠不同,因此值得使用專門為資料擷取使用案例而建置的工具。
RTK Query 從其他已率先提出資料擷取解決方案的工具中汲取靈感,例如 Apollo Client、React Query、Urql 和 SWR,但為其 API 設計新增了獨特方法
- 資料擷取和快取邏輯建立在 Redux Toolkit 的
createSlice和createAsyncThunkAPI 之上 - 由於 Redux Toolkit 與 UI 無關,因此 RTK Query 的功能可用於任何 UI 層
- API 端點會事先定義,包括如何從引數產生查詢參數,以及如何轉換回應以進行快取
- RTK Query 也可以產生 React hooks,封裝整個資料擷取流程,提供
data和isFetching欄位給元件,並在元件掛載和卸載時管理快取資料的生命週期 - RTK Query 提供「快取條目生命週期」選項,在擷取初始資料後,透過 Websocket 訊息串流快取更新等使用案例
- 我們有從 OpenAPI 和 GraphQL 架構產生 API 切片的早期工作範例
- 最後,RTK Query 完全使用 TypeScript 編寫,並旨在提供絕佳的 TS 使用體驗
包含內容
API
RTK Query 包含在 Redux Toolkit 核心套件的安裝中。它可透過以下兩個進入點取得
import { createApi } from '@reduxjs/toolkit/query'
/* React-specific entry point that automatically generates
hooks corresponding to the defined endpoints */
import { createApi } from '@reduxjs/toolkit/query/react'
RTK Query 主要包含兩個 API
createApi():RTK Query 功能的核心。它讓您可以定義一組端點,說明如何從一系列端點擷取資料,包括如何擷取和轉換資料的設定。在多數情況下,您應該在每個應用程式中使用一次,原則上為「每個基本 URL 一個 API 切片」fetchBaseQuery():fetch的一個小包裝,旨在簡化要求。預計為多數使用者在createApi中使用的建議baseQuery
套件大小
RTK Query 會為您的應用程式套件大小新增一個固定的單次數量。由於 RTK Query 建立在 Redux Toolkit 和 React-Redux 之上,因此新增的大小會根據您是否已在應用程式中使用這些而有所不同。估計的最小 + gzip 套件大小為
- 如果您已使用 RTK:RTK Query 約 9kb,hooks 約 2kb
- 如果您尚未使用 RTK
- 沒有 React:RTK + 相依項 + RTK Query 為 17 kB
- 有 React:19kB + React-Redux,這是同儕相依項
新增其他端點定義應該只會根據 endpoints 定義中的實際程式碼增加大小,通常只會增加幾個位元組
RTK Query 中包含的功能很快就能彌補新增的套件大小,而且消除手寫資料擷取邏輯對於大多數有意義的應用程式來說,應該會大幅改善大小
在 RTK Query 快取中思考
Redux 一直強調可預測性和明確的行為。Redux 中沒有「魔法」——你應該能夠理解應用程式中發生的情況,因為所有 Redux 邏輯都遵循相同的基本模式,即透過 reducer 派發動作並更新狀態。這確實表示有時你必須撰寫更多程式碼才能讓事情發生,但權衡之下,資料流和行為會非常清楚。
Redux Toolkit 核心 API 不會變更 Redux 應用程式中的任何基本資料流你仍然會派發動作並撰寫 reducer,只是程式碼比手動撰寫所有邏輯來得少。RTK Query 也是如此。它是一個額外的抽象層級,但在內部,它仍然執行我們已經看過的管理非同步要求及其回應的確切步驟。
不過,當你使用 RTK Query 時,確實會發生心態轉變。我們不再思考「管理狀態」本身。相反地,我們現在思考「管理快取資料」。我們不再嘗試自己撰寫 reducer,而是專注於定義「這些資料從何而來?」、「應該如何傳送這個更新?」、「這個快取資料應該何時重新擷取?」,以及「快取資料應該如何更新?」。資料如何被擷取、儲存和擷回變成我們不再需要擔心的實作細節。
我們將在繼續時看到這種心態轉變如何應用。
設定 RTK Query
我們的範例應用程式已經可以運作,但現在是時候將所有非同步邏輯遷移到使用 RTK Query。在我們進行的過程中,我們將看到如何使用 RTK Query 的所有主要功能,以及如何將現有的 createAsyncThunk 和 createSlice 用法遷移到使用 RTK Query API。
定義 API 片段
先前,我們為每一個不同的資料類型(例如文章、使用者和通知)定義了個別的「片段」。每個片段都有自己的 reducer,定義自己的動作和 thunk,並分別快取該資料類型的項目。
使用 RTK Query,管理快取資料的邏輯集中到每個應用程式的單一「API 片段」中。就像你在每個應用程式中只有一個 Redux 儲存體一樣,我們現在為所有快取資料只有一個片段。
我們將從定義一個新的 apiSlice.js 檔案開始。由於這不特定於我們已經撰寫的任何其他「功能」,我們將新增一個 features/api/ 資料夾,並將 apiSlice.js 放入其中。讓我們填寫 API 片段檔案,然後分解裡面的程式碼,看看它在做什麼
// Import the RTK Query methods from the React-specific entry point
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
// Define our single API slice object
export const apiSlice = createApi({
// The cache reducer expects to be added at `state.api` (already default - this is optional)
reducerPath: 'api',
// All of our requests will have URLs starting with '/fakeApi'
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// The "endpoints" represent operations and requests for this server
endpoints: builder => ({
// The `getPosts` endpoint is a "query" operation that returns data
getPosts: builder.query({
// The URL for the request is '/fakeApi/posts'
query: () => '/posts'
})
})
})
// Export the auto-generated hook for the `getPosts` query endpoint
export const { useGetPostsQuery } = apiSlice
RTK Query 的功能基於一個稱為 createApi 的單一方法。我們到目前為止看過的所有 Redux Toolkit API 都是與 UI 無關的,並且可以用於任何 UI 層。RTK Query 核心邏輯也是如此。不過,RTK Query 也包含 createApi 的 React 專用版本,而且由於我們同時使用 RTK 和 React,我們需要使用它來利用 RTK 的 React 整合。因此,我們特別從 '@reduxjs/toolkit/query/react' 匯入。
您的應用程式預期只有一個 createApi 呼叫。這個 API 區段應包含所有與相同基本 URL 通訊的端點定義。例如,端點 /api/posts 和 /api/users 都從同一伺服器擷取資料,因此它們會放在同一個 API 區段中。如果您的應用程式確實從多個伺服器擷取資料,您可以指定每個端點中的完整 URL,或必要時為每個伺服器建立個別的 API 區段。
端點通常直接在 createApi 呼叫中定義。如果您想將端點分割成多個檔案,請參閱文件第 8 部分的 「注入端點」區段!
API 區段參數
當我們呼叫 createApi 時,有兩個欄位是必要的
baseQuery:一個知道如何從伺服器擷取資料的函式。RTK Query 包含fetchBaseQuery,一個小包裝器,用於標準fetch()函式,可處理請求和回應的典型處理。當我們建立一個fetchBaseQuery執行個體時,我們可以傳入所有未來請求的基本 URL,以及覆寫修改請求標頭等行為。endpoints:我們定義的一組用於與此伺服器互動的操作。端點可以是查詢,它會傳回資料以進行快取,或突變,它會將更新傳送至伺服器。端點使用接受builder參數並傳回包含使用builder.query()和builder.mutation()建立的端點定義的物件的回呼函式來定義。
createApi 也接受 reducerPath 欄位,它定義產生式簡化器的預期頂層狀態區段欄位。對於我們的其他區段,例如 postsSlice,無法保證它會用於更新 state.posts - 我們可以將簡化器附加到根狀態中的任何位置,例如 someOtherField: postsReducer。在此,createApi 預期我們告訴它當我們將快取簡化器新增至儲存時,快取狀態將存在的位置。如果您未提供 reducerPath 選項,它會預設為 'api',因此您的所有 RTKQ 快取資料都會儲存在 state.api 下。
如果您忘記將 reducer 加入 store,或在與 reducerPath 中指定的 key 不同的 key 中附加它,RTKQ 將會記錄錯誤,讓您知道需要修正此問題。
定義端點
所有要求的 URL 的第一部分在 fetchBaseQuery 定義中定義為 '/fakeApi'。
對於我們的步驟,我們想要新增一個端點,它將從假的 API 伺服器傳回所有文章的清單。我們將包含一個稱為 getPosts 的端點,並使用 builder.query() 將其定義為查詢端點。此方法接受許多選項,用於設定如何提出要求和處理回應。現在,我們只需要透過定義 query 選項,並使用傳回 URL 字串的回呼函式 () => '/posts' 來提供 URL 路徑的剩餘部分即可。
預設情況下,查詢端點將使用 GET HTTP 要求,但您可以透過傳回一個物件(例如 {url: '/posts', method: 'POST', body: newPost})來覆寫它,而不要只傳回 URL 字串本身。您也可以透過這種方式為要求定義其他幾個選項,例如設定標頭。
匯出 API 切片和 Hooks
在我們較早的切片檔案中,我們只匯出了動作建立器和切片 reducer,因為這是在其他檔案中所需要的。有了 RTK Query,我們通常會匯出整個「API 切片」物件本身,因為它有幾個欄位可能很有用。
最後,仔細查看此檔案的最後一行。這個 useGetPostsQuery 值從何而來?
RTK Query 的 React 整合將自動為我們定義的每個端點產生 React hooks!這些 hooks 封裝了在元件掛載時觸發要求,以及在要求處理和資料可用的時候重新呈現元件的程序。我們可以從這個 API 切片檔案中匯出這些 hooks,以便在我們的 React 元件中使用。
hooks 會根據標準慣例自動命名
use,任何 React hook 的一般前綴- 端點的名稱,大寫
- 端點的類型,
Query或Mutation
在這個案例中,我們的端點是 getPosts,而且它是一個查詢端點,所以產生的 hook 是 useGetPostsQuery。
設定 Store
我們現在需要將 API 區段連接到我們的 Redux 儲存。我們可以修改現有的 store.js 檔案,將 API 區段的快取減速器新增到狀態中。此外,API 區段會產生一個自訂中介軟體,需要新增到儲存中。這個中介軟體必須也要新增 - 它會管理快取生命週期和到期時間。
import postsReducer from '../features/posts/postsSlice'
import usersReducer from '../features/users/usersSlice'
import notificationsReducer from '../features/notifications/notificationsSlice'
import { apiSlice } from '../features/api/apiSlice'
export default configureStore({
reducer: {
posts: postsReducer,
users: usersReducer,
notifications: notificationsReducer,
[apiSlice.reducerPath]: apiSlice.reducer
},
middleware: getDefaultMiddleware =>
getDefaultMiddleware().concat(apiSlice.middleware)
})
我們可以在 reducer 參數中將 apiSlice.reducerPath 欄位重新用作計算金鑰,以確保快取減速器新增到正確的位置。
我們需要將所有現有的標準中介軟體(例如 redux-thunk)保留在儲存設定中,而 API 區段的中介軟體通常會在這些中介軟體之後。我們可以透過提供 middleware 參數給 configureStore,呼叫提供的 getDefaultMiddleware() 方法,並在傳回的中介軟體陣列的結尾新增 apiSlice.middleware 來執行此操作。
使用查詢顯示文章
在元件中使用查詢掛勾
現在我們已經定義了 API 區段並將其新增到儲存中,我們可以將產生的 useGetPostsQuery 掛勾匯入到我們的 <PostsList> 元件中,並在那裡使用它。
目前,<PostsList> 特別匯入了 useSelector、useDispatch 和 useEffect,從儲存中讀取文章資料和載入狀態,並在掛載時派送 fetchPosts() thunk 以觸發資料擷取。useGetPostsQueryHook 取代了所有這些!
讓我們看看使用這個掛勾時 <PostsList> 的外觀
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '../../components/Spinner'
import { PostAuthor } from './PostAuthor'
import { TimeAgo } from './TimeAgo'
import { ReactionButtons } from './ReactionButtons'
import { useGetPostsQuery } from '../api/apiSlice'
let PostExcerpt = ({ post }) => {
return (
<article className="post-excerpt" key={post.id}>
<h3>{post.title}</h3>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content.substring(0, 100)}</p>
<ReactionButtons post={post} />
<Link to={`/posts/${post.id}`} className="button muted-button">
View Post
</Link>
</article>
)
}
export const PostsList = () => {
const {
data: posts,
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = posts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
從概念上來說,<PostsList> 仍然執行與之前相同的所有工作,但我們能夠用單一呼叫 useGetPostsQuery() 取代多個 useSelector 呼叫和 useEffect 派送。
你通常應該使用查詢掛勾來存取元件中的快取資料 - 你不應該撰寫自己的 useSelector 呼叫來存取擷取的資料或 useEffect 呼叫來觸發擷取!
每個產生的查詢掛勾會傳回一個包含多個欄位的「結果」物件,包括
data:伺服器的實際回應內容。在收到回應之前,這個欄位將會是undefined。isLoading:一個布林值,表示這個掛勾目前是否正在對伺服器進行第一次請求。(請注意,如果參數變更為請求不同的資料,isLoading將會保持為 false。)isFetching:一個布林值,表示掛鉤目前是否正在對伺服器進行任何要求isSuccess:一個布林值,表示掛鉤是否已進行成功的要求,且有快取資料可用(例如,現在應已定義data)isError:一個布林值,表示最後一個要求是否有錯誤error:一個序列化的錯誤物件
通常會從結果物件解構欄位,並可能將 data 重新命名為更具體的變數,例如 posts,以描述其包含的內容。然後,我們可以使用狀態布林值和 data/error 欄位來呈現我們想要的 UI。不過,如果你使用的是 TypeScript,你可能需要維持原始物件不變,並在條件檢查中將標記參照為 result.isSuccess,以便 TS 能正確推論 data 是有效的。
先前,我們從儲存庫中選取一串文章 ID,傳遞文章 ID 給每個 <PostExcerpt> 元件,並從儲存庫中個別選取每個 Post 物件。由於 posts 陣列已包含所有文章物件,我們已改回傳遞文章物件本身作為道具。
排序文章
很不幸地,文章現在顯示的順序不對。先前,我們使用 createEntityAdapter 的排序選項,在 reducer 層級依日期對它們進行排序。由於 API 片段只快取從伺服器傳回的精確陣列,因此沒有進行特定的排序 - 我們所得到的順序就是伺服器傳回的順序。
有幾種不同的選項可以處理這個問題。目前,我們會在 <PostsList> 內部進行排序,稍後我們會討論其他選項及其權衡利弊。
我們不能直接呼叫 posts.sort(),因為 Array.sort() 會變更現有陣列,所以我們需要先複製一份。為避免在每次重新呈現時重新排序,我們可以在 useMemo() 掛鉤中進行排序。我們也想要給 posts 一個預設的空陣列,以防它為 undefined,這樣我們永遠都有陣列可以進行排序。
// omit setup
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
// Sort posts in descending chronological order
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = sortedPosts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
顯示個別文章
我們已更新 <PostsList> 以擷取所有文章的清單,而且我們在清單中顯示每個 Post 的片段。但是,如果我們按一下其中任何文章的「檢視文章」,我們的 <SinglePostPage> 元件將無法在舊的 state.posts 區段中找到文章,並會顯示「找不到文章!」錯誤。我們需要更新 <SinglePostPage> 以同時使用 RTK Query。
我們有幾種方法可以執行此操作。其中一種方法是讓 <SinglePostPage> 呼叫相同的 useGetPostsQuery() 勾子,取得文章的完整陣列,並找出它需要顯示的單一 Post 物件。查詢勾子也有一個 selectFromResult 選項,允許我們在勾子本身中較早執行相同的查詢 - 我們稍後會看到此動作。
相反地,我們將嘗試新增另一個端點定義,讓我們可以根據其 ID 從伺服器要求單篇文章。這有點多餘,但它將讓我們看到如何使用 RTK Query 根據引數自訂查詢要求。
新增單篇文章查詢端點
在 apiSlice.js 中,我們將新增另一個查詢端點定義,稱為 getPost(這次沒有「s」)
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts'
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
})
})
})
export const { useGetPostsQuery, useGetPostQuery } = apiSlice
getPost 端點看起來很像現有的 getPosts 端點,但 query 參數不同。在此,query 會取得一個稱為 postId 的引數,而且我們使用該 postId 來建構伺服器 URL。這樣,我們就可以針對只有一個特定 Post 物件提出伺服器要求。
這也會產生一個新的 useGetPostQuery 勾子,所以我們也匯出它。
查詢引數和快取金鑰
我們的 <SinglePostPage> 目前根據 ID 從 state.posts 讀取一個 Post 條目。我們需要更新它以呼叫新的 useGetPostQuery 勾子,並使用與主清單類似的載入狀態。
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '../../components/Spinner'
import { useGetPostQuery } from '../api/apiSlice'
import { PostAuthor } from './PostAuthor'
import { TimeAgo } from './TimeAgo'
import { ReactionButtons } from './ReactionButtons'
export const SinglePostPage = ({ match }) => {
const { postId } = match.params
const { data: post, isFetching, isSuccess } = useGetPostQuery(postId)
let content
if (isFetching) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = (
<article className="post">
<h2>{post.title}</h2>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content}</p>
<ReactionButtons post={post} />
<Link to={`/editPost/${post.id}`} className="button">
Edit Post
</Link>
</article>
)
}
return <section>{content}</section>
}
請注意,我們從路由比對中讀取 postId,並將它作為引數傳遞給 useGetPostQuery。然後查詢勾子會使用它來建構要求 URL,並擷取這個特定的 Post 物件。
那麼,所有這些資料是如何快取的?讓我們為其中一則貼文按一下「檢視貼文」,然後看看此時 Redux 儲存庫內有什麼。
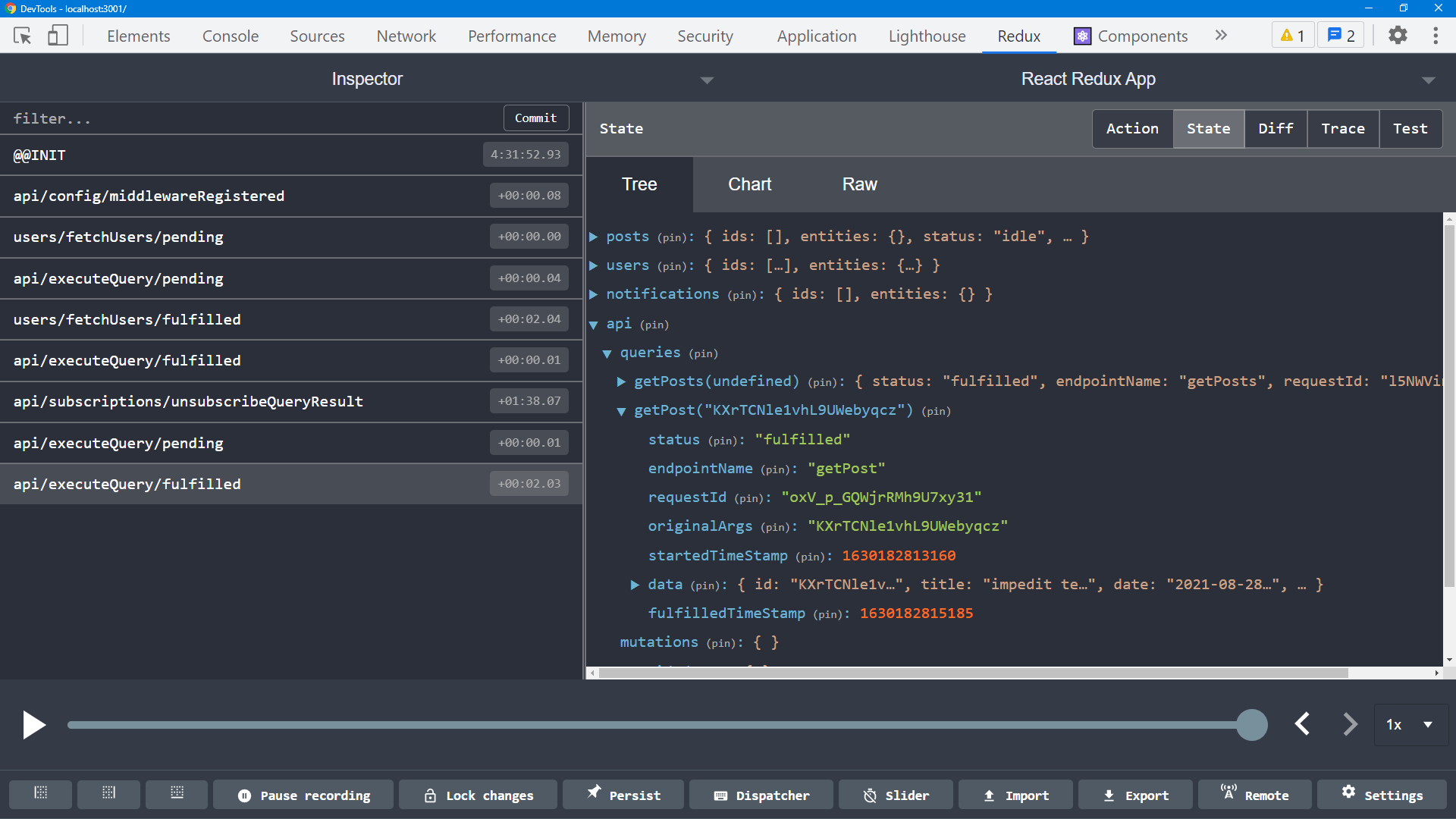
我們可以看到,我們有一個頂層的 state.api 切片,這符合儲存庫設定。在裡面有一個稱為 queries 的區段,它目前有兩個項目。金鑰 getPosts(undefined) 代表我們使用 getPosts 端點所做的要求的元資料和回應內容。類似地,金鑰 getPost('abcd1234') 是針對我們剛剛針對這則貼文所做的特定要求。
RTK Query 為每個獨特的端點 + 引數組合建立一個「快取金鑰」,並分別儲存每個快取金鑰的結果。這表示你可以多次使用相同的查詢掛勾,傳遞不同的查詢參數,每個結果都會分別快取在 Redux 儲存庫中。
如果你需要在多個元件中使用相同的資料,只要在每個元件中使用相同的引數呼叫相同的查詢掛勾即可!例如,你可以在三個不同的元件中呼叫 useGetPostQuery('123'),RTK Query 會確保資料僅擷取一次,每個元件會視需要重新呈現。
另外要注意的是,查詢參數必須是單一值!如果你需要傳遞多個參數,你必須傳遞包含多個欄位的物件(與 createAsyncThunk 完全相同)。RTK Query 會對欄位進行「淺層穩定」比較,如果其中任何欄位已變更,則會重新擷取資料。
請注意,左側清單中動作的名稱更為通用且描述性較低:api/executeQuery/fulfilled,而不是 posts/fetchPosts/fulfilled。這是使用額外抽象層的權衡。個別動作確實包含 action.meta.arg.endpointName 下的特定端點名稱,但它在動作記錄清單中並不容易看到。
Redux DevTools 有個「RTK Query」標籤,專門以更實用的格式顯示 RTK Query 資料。這包括每個端點和快取結果的資訊、查詢時間的統計資料,以及更多內容
使用突變建立文章
我們已經了解如何透過定義「查詢」端點從伺服器擷取資料,但要如何將更新傳送至伺服器?
RTK Query 讓我們可以定義突變端點,用於更新伺服器上的資料。讓我們新增一個突變,讓它可以讓我們新增一篇文章。
新增新增文章突變端點
新增突變端點與新增查詢端點非常類似。最大的不同在於我們使用 `builder.mutation()` 而不是 `builder.query()` 來定義端點。此外,我們現在需要將 HTTP 方法變更為 `'POST'` 要求,並且我們也必須提供要求的主體。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts'
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
// Include the entire post object as the body of the request
body: initialPost
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation
} = apiSlice
在這裡,我們的 `query` 選項傳回包含 `{url, method, body}` 的物件。由於我們使用 `fetchBaseQuery` 進行要求,`body` 欄位會自動為我們序列化為 JSON。
與查詢端點一樣,API 切片會自動為突變端點產生 React 勾子,在本例中為 `useAddNewPostMutation`。
在元件中使用突變勾子
我們的 `<AddPostForm>` 已經在我們按下「儲存文章」按鈕時,派送非同步 thunk 來新增文章。為此,它必須匯入 `useDispatch` 和 `addNewPost` thunk。突變勾子會取代這兩個,而使用模式非常類似。
import React, { useState } from 'react'
import { useSelector } from 'react-redux'
import { Spinner } from '../../components/Spinner'
import { useAddNewPostMutation } from '../api/apiSlice'
import { selectAllUsers } from '../users/usersSlice'
export const AddPostForm = () => {
const [title, setTitle] = useState('')
const [content, setContent] = useState('')
const [userId, setUserId] = useState('')
const [addNewPost, { isLoading }] = useAddNewPostMutation()
const users = useSelector(selectAllUsers)
const onTitleChanged = e => setTitle(e.target.value)
const onContentChanged = e => setContent(e.target.value)
const onAuthorChanged = e => setUserId(e.target.value)
const canSave = [title, content, userId].every(Boolean) && !isLoading
const onSavePostClicked = async () => {
if (canSave) {
try {
await addNewPost({ title, content, user: userId }).unwrap()
setTitle('')
setContent('')
setUserId('')
} catch (err) {
console.error('Failed to save the post: ', err)
}
}
}
// omit rendering logic
}
突變勾子會傳回包含兩個值的陣列
- 第一個值是「觸發函式」。呼叫時,它會向伺服器提出要求,並附上你提供的任何引數。這實際上就像一個已經包裝好,可以立即派送自己的 thunk。
- 第二個值是一個物件,其中包含有關目前進行中要求的元資料(如果有的話)。這包括一個 `isLoading` 旗標,用於指出要求是否正在進行中。
我們可以用觸發函式和 `useAddNewPostMutation` 勾子的 `isLoading` 旗標取代現有的 thunk 派送和元件載入狀態,而元件的其他部分則保持不變。
與 thunk 派送一樣,我們使用初始文章物件呼叫 `addNewPost`。這會傳回一個特殊的 `Promise`,其中包含一個 `unwrap()` 方法,而我們可以使用 `await addNewPost().unwrap()` 來使用標準的 `try/catch` 區塊處理任何潛在的錯誤。
更新快取資料
當我們按一下「儲存文章」時,可以在瀏覽器 DevTools 的「網路」標籤中查看,並確認 HTTP POST 要求已成功。但是,如果我們返回,新的文章不會顯示在我們的 <PostsList> 中。我們在記憶體中仍然有相同的快取資料。
我們需要告知 RTK Query 更新其快取的文章清單,以便我們可以看到剛才新增的文章。
手動重新擷取文章
第一個選項是手動強制 RTK Query 重新擷取特定端點的資料。查詢掛鉤結果物件包含一個 refetch 函式,我們可以呼叫它來強制重新擷取。我們可以暫時在 <PostsList> 中新增一個「重新擷取文章」按鈕,並在新增一篇文章後按一下該按鈕。
此外,我們之前看到查詢掛鉤同時具有 isLoading 旗標(如果這是資料的第一次要求,則為 true)和 isFetching 旗標(在任何資料要求進行中時為 true)。我們可以查看 isFetching 旗標,並在重新擷取進行中時,再次用載入指示器取代所有文章清單。但是,那可能會有點惱人,而且 - 我們已經有所有這些文章,為什麼我們要完全隱藏它們?
相反地,我們可以讓現有的文章清單部分透明,以表示資料已過時,但在重新擷取進行時讓它們保持可見。一旦要求完成,我們就可以恢復正常顯示文章清單。
import React, { useMemo } from 'react'
import { Link } from 'react-router-dom'
import classnames from 'classnames'
// omit other imports and PostExcerpt
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
const renderedPosts = sortedPosts.map(post => (
<PostExcerpt key={post.id} post={post} />
))
const containerClassname = classnames('posts-container', {
disabled: isFetching
})
content = <div className={containerClassname}>{renderedPosts}</div>
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
<button onClick={refetch}>Refetch Posts</button>
{content}
</section>
)
}
如果我們新增一篇文章,然後按一下「重新擷取文章」,我們現在應該會看到文章清單變成半透明,持續幾秒鐘,然後重新呈現,並在頂端新增新的文章。
使用快取無效化進行自動更新
偶爾需要使用者手動按一下以重新擷取資料,但這絕對不是正常使用的好方法。
我們知道我們的「伺服器」擁有所有文章的完整清單,包括我們剛才新增的文章。理想情況下,我們希望我們的應用程式在變更要求完成後,自動重新擷取已更新的文章清單。這樣,我們就知道我們的用戶端快取資料與伺服器上的資料同步。
RTK Query 讓我們定義查詢和變異之間的關係,以使用「標籤」啟用自動資料重新擷取。一個「標籤」是一個字串或小物件,讓您可以命名特定類型的資料,並失效快取的部分。當快取標籤失效時,RTK Query 會自動重新擷取標記有該標籤的端點。
基本標籤用法需要將三則資訊新增到我們的 API 片段
- API 片段物件中的根
tagTypes欄位,宣告一個字串標籤名稱陣列,用於資料類型,例如'Post' - 查詢端點中的
providesTags陣列,列出描述該查詢中資料的一組標籤 - 變異端點中的
invalidatesTags陣列,列出每次執行該變異時會失效的一組標籤
我們可以將一個名為 'Post' 的單一標籤新增到我們的 API 片段,這樣我們就可以在每次新增新文章時自動重新擷取我們的 getPosts 端點
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
})
這就是我們所需要的!現在,如果我們按一下「儲存文章」,您應該會看到 <PostsList> 元件在幾秒鐘後自動變灰,然後重新呈現,將新增加的文章置於頂端。
請注意,這裡的文字字串 'Post' 沒有什麼特別之處。我們可以稱它為 'Fred'、'qwerty' 或其他任何名稱。它只需要在每個欄位中都是相同的字串,這樣 RTK Query 才能知道「當此變異發生時,使所有列出相同標籤字串的端點失效」。
您已學到的內容
使用 RTK Query,管理資料擷取、快取和載入狀態的實際細節會被抽象化。這大幅簡化了應用程式程式碼,讓我們可以專注於預期的應用程式行為等較高層級的考量。由於 RTK Query 是使用我們已經看過的 Redux Toolkit API 實作的,我們仍然可以使用 Redux DevTools 來查看我們狀態隨時間的變化。
- RTK Query 是 Redux Toolkit 中包含的資料擷取和快取解決方案
- RTK Query 為您抽象化管理快取伺服器資料的程序,並消除了撰寫載入狀態、儲存結果和發出請求的邏輯需求
- RTK Query 建立在 Redux 中使用的相同模式之上,例如非同步 thunk
- RTK Query 每個應用程式使用一個「API 片段」,使用
createApi定義- RTK Query 提供
createApi的 UI 不可知和 React 特定的版本 - API 片段定義多個「端點」用於不同的伺服器操作
- 如果使用 React 整合,API 切片包含自動產生的 React 勾子
- RTK Query 提供
- 查詢端點允許從伺服器擷取和快取資料
- 查詢勾子傳回
data值,加上載入狀態旗標 - 查詢可以手動重新擷取,或使用快取無效化的「標籤」自動重新擷取
- 查詢勾子傳回
- 變異端點允許更新伺服器上的資料
- 變異勾子傳回一個「觸發」函式,用於傳送更新要求,加上載入狀態
- 觸發函式傳回一個 Promise,可以「解開」並等待
下一步?
RTK Query 提供穩定的預設行為,但同時也包含許多選項,用於自訂請求的管理方式和快取資料的使用方式。在 第 8 部分:RTK Query 進階模式 中,我們將了解如何使用這些選項來實作有用的功能,例如樂觀更新。